The Computer Doesn’t Know My Product!
All Situation Room examples are constructed and not descriptions of actual events.

Published on: November 11, 2023
Walter Routh
Share This Article with the Stability Community!
What is the stability situation?
Late last year we started tracking and trending stability data in real time using software that analyzes results entered by the testing lab each day. The system is designed to flag potentially aberrant results and send notifications to stability and lab management. The intention is for the labs to initially investigate the value to ensure no lab error caused the panic.
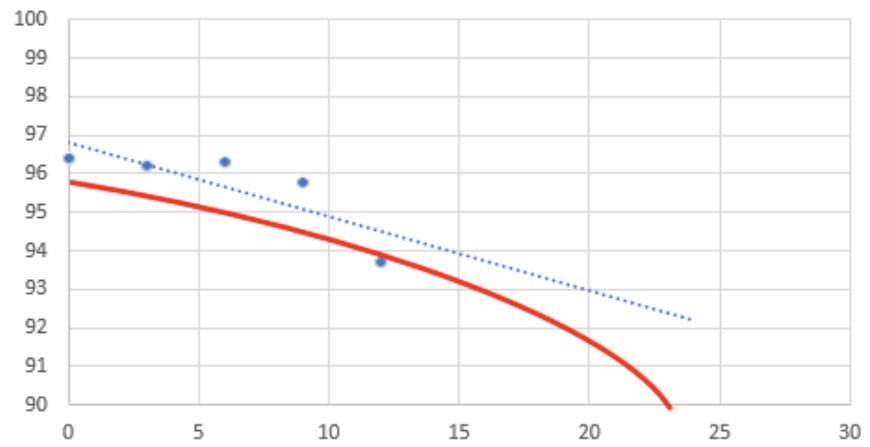
Last week one of our established oral dosage antacid type drugs was flagged as aberrant for potency at the 12-month interval and was projected to fail at 24 months vs. its 48-month shelf life.
Visually I can see that the first few intervals are flat, but on the lower side, and the 12-month interval suddenly drops. With such extensive historical data, stability folk like me are not worried, but the lab and QA management are ready to initiate a recall! The lab sees no hint of error on their side (of course) after their investigation that did not include any retesting.
I believe the batch was initially 1 to 2% lower than the main population, but that has been seen several times in the past and is well within the process limits. The relatively flat degradation pattern through 9-months is typical, so either the 12-month data is erroneous or simply represents a single sample on the low end, but still well within specification (>90%). I think we’re seeing some of the key pain points of our automated statistical tracking process and it just need’s tweaking—where should we go from here?
How should this be resolved?
Justify a potency re-test or perhaps add a data point for the next monthly interval? What would you do?
We Want to Hear Your Thoughts!
June 6, 2026

A stability manager has become aware that several colleagues from different companies are changing a key practice based on a perceived industry trend that comes with significant cost savings as well. Should he follow suit or stay in his comfort zone?
May 2, 2026

The lab received a stability sample labeled with the incorrect test interval. Is the study compromised? Can it be salvaged enough to submit the data in a filing?
March 28, 2026

A stability manager regrets not pushing harder for funding years earlier for a digitalization program. Now, when it is critical she’s drowning in options and burning up under executive scrutiny.
Share your questions and experiences
A stabilitarian encounters new situations every day. StabilityHub’s discussion forums give Stabilitarians an opportunity to ask questions and offer solutions to specific scenarios. Join in the conversations with other Stabilitiarians and share your knowledge!
A stabilitarian encounters new situations every day. StabilityHub’s discussion forums give Stabilitarians an opportunity to ask questions and offer solutions to specific scenarios. Join in the conversations with other Stabilitiarians and share your knowledge!